marginalia, spiders and bug hunting
Published: techTroubleshooting on a smallweb search engine.
I'm quite the fan of getting off the beaten path, and so that has led me to be quite the fan of what they call "the small web". And as such, I quite like marginalia. It is a one-man project attempting to index and catalog everything off the beaten path (hence, "marginalia", a very nice word), and I genuinely think it stands to become more useful than many big-name search engines for many use cases quite soon. Please give it a look sometime. What's more, if you're reading this as someone curating your own website on here, please submit it for crawling! I'll get into detail on how to do that in here.
A quick overview for those unfamiliar with how a search engine operates:
What is a spider?
It is not a creepy crawly thing on 8 legs of the arachnid family.
A webcrawler (spider) is how a search engine finds sites to show everyone else. A good bit of traffic on the web at any given time is these robots going around finding stuff to index (pull apart for analysis of search terms and display of content) and serve up to everyone else. Getting crawled means that your site is more discoverable, which means you should get some more traffic in the future. Since this traffic is from search engine users looking for specific things, it hopefully means that it is a visit from someone that can get value from your site!
Spiders do not crawl every site every day, so it is important to have your affairs in order for when they do visit. This usually takes the form of a few special files that help them out, namely robots.txt and sitemap.xml. We're only gonna worry about robots this time around, since that's enough to at least get indexed properly.
Unfortunately, a large part of this game has been taken over by what's called "SEO" (search engine optimization). The "optimization" in question here is not about creating more value for the people using the engine, but playing the game of "what is google/bing/etc" looking for in my site that bumps it up the list of relevant results when someone types in a given query. This is obviously summarized, but this whole game, along with everyone locking content behind logins (the so-called "grey-web") has led to massive decreases in quality in search results and the domination of a few sites of questionable quality that shall not be named here in all results.
There are a few places, such as marginalia, that actively utilize a topsy-turvy indexing algorithm that instead prioritizes sites that appear to be human-made rather than seo-optimized.
Getting added.
There's a writeup on marginalia itself on this, but I figure I'll detail it out here as well. How to get your own site crawled: First, create a robots.txt, marginalia requests you specifically add an allow for their crawler, as they respect robots.txt (the file itself is somewhat more of a "be polite" thing than an actual command). You can disallow crawlers as well, but I leave adding those rules as an exercise to the reader. (note that if this doesn't exist, big places like google just assume they have the rights to crawl you anyway)
So copy this to your robots.txt file:
User-agent: search.marginalia.nu
Allow: /
From there, you have a few options:
- Neocities is rather well-webbed, so there's a good chance that your site might actually have been seen before by one of the spiders. To check, you can go to the search engine and search for
site:yoursite.comIf this is the case, all you gotta do is click the button that gives permission for the site to be crawled! - It's worth giving github a shot (especially and not least because you should really consider using a ssg and ci/cd for your site, perhaps I'll do a writeup on that as well), but you can also email Mr Marginalia himself via kontakt@marginalia.nu with a list of your domains (he's very nice and very responsive!)
- Finally, you can submit a pull request to get added to the list directly. It's as simple as having a github account and just making the edit here since its only a one-liner. Take this part seriously! "Telling me lets me fix whatever problem there is much faster, and if you are experiencing problems, then so are probably others as well."
That said, now just sit tight a few days.
If all is well, you can search for site:yoursite.com and it ought to show up as crawled! You should start getting traffic here and there from marginalia, and you're helping to support discoverability in the small web. If not, well, all you really have to do is ask for some help;
Troubleshootin'
For me, I had a few issues at first. I searched for my domains every so often, but nothing came up. When I went to look at the site page, I got this:
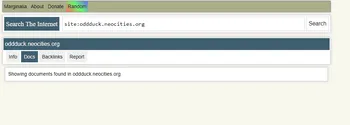
Clearly, my site has more than 0 documents.
Naturally, I assumed this a me issue, and so tried a few things on my end. Editing my sitemap, editing my robots, and just generally poking around on marginalia thinking I'd just missed a button somewhere. I sat on this far too long, but I finally emailed about this last month, and within hours and a few quick email responses later the issue was found and a temporary fix was built. It started picking up stuff off the old version of my site, and currently I'm just waiting for the crawler to come back around and try crawling everything again. To that end, I'm putting this up a bit before that in the hope it gets crawled too and people can find this article if they're having similar problems.
The only way these sorts of projects get the level of polish they need to shine is for lots of people to use them and report whatever breaks, or seems off, so make sure to! Even if it seems like it's on your end, even if it seems minor, it's very likely to be causing issues for many other people. As a software dev myself, I can say this sort of end-user testing is invaluable for making any application truly robust, but obviously it only goes as far as communication from end users. We're all supporting each other in cultivating a healthy ecosystem for the growth of real, personal websites again. So participate where you can, even if it's just submitting your website for crawling; every little bit makes the whole garden greener.